
The True Cost of Running AI Agents in Production
Raw API pricing is 30-50% of total agent cost. This guide breaks down where the money actually goes, from orchestration overhead to the Jevons paradox, and how to cut spend without cutting capability.
Chain-of-Thought Prompting: When It Works, When It Fails, and Why
Chain-of-thought is the most studied prompting technique in AI, and the most misapplied. A decision framework for when it helps, when it hurts, and what it costs.

AI Alignment Explained: What It Actually Means to Make AI Do What We Want
What AI alignment actually means as an engineering problem. The three core challenges, the techniques that exist today, and why agents make everything harder.

How to Read AI Research Papers Without a PhD
A practical guide to reading AI research papers. Learn the three-pass method, spot red flags in benchmarks and methodology, and build a sustainable reading practice.
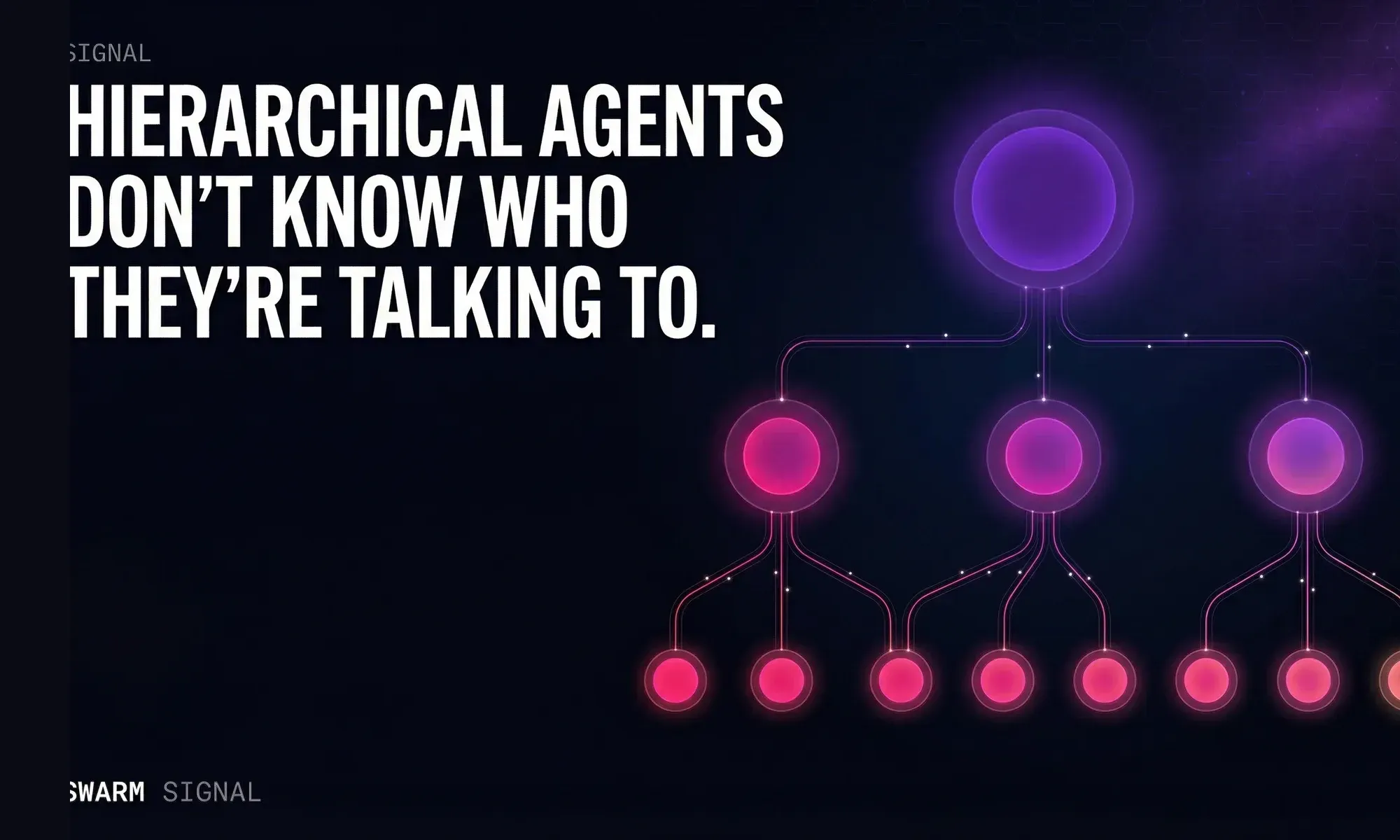
Hierarchical Agents Don't Know Who They're Talking To
Roughly 70% of Earth science datasets hosted in large repositories like PANGAEA go uncited after publication. The data exists. The agents can access it....

When Your Agent Stops Using Tools
Reinforcement learning was supposed to teach agents to use tools fluently. Instead, researchers are watching a consistent failure mode: models trained...

The Protocol Wars Are Ending. Here's What Actually Happened.
Anthropic's MCP and Google's A2A joined the Linux Foundation. IBM killed its own protocol to back A2A. 146 organizations signed on. The wars are ending.

LLM-Powered Swarms and the 300x Overhead Nobody Wants to Talk About
SwarmBench tested 13 LLMs on swarm coordination tasks. The results show catastrophic overhead and communication that doesn't actually help.

The Swarm That Fakes Consensus
Twenty-two researchers across four continents show how agent swarms fabricate consensus, infiltrate communities, and poison the training data of future AI models.

Attention Heads Are the New Inference Budget
Models that can technically process 128K tokens routinely fail on tasks requiring reasoning across 32K. That gap isn't a context window problem. It's an...