
Models Training Models: The Promise and Peril of Synthetic Data
Microsoft's Phi-4 trained on more than 50% synthetic data and beat GPT-4o on graduate science benchmarks. The old rules about training data are changing fast.

The 12-to-72 Problem: Computer-Use Agents Hit Human Scores but Miss the Point
Computer-use agents jumped from 12% to 72% on OSWorld in 18 months. The scores look like progress. The latency and efficiency numbers tell a different story.

Agents Can Connect. They Still Can't Communicate.
MCP and A2A solved the plumbing. The hard part — agents actually communicating meaning — remains wide open.

More Context Doesn't Kill RAG. It Just Changes the Fight.
Long-context LLMs now hit a million tokens, but a persistent 10% accuracy gap and punishing costs keep RAG very much in the fight.

Obsidian's CLI Turns Your Second Brain Into an API
Obsidian 1.12 ships an official CLI with 100+ commands. Here's what works, what breaks, and why AI developers should care.

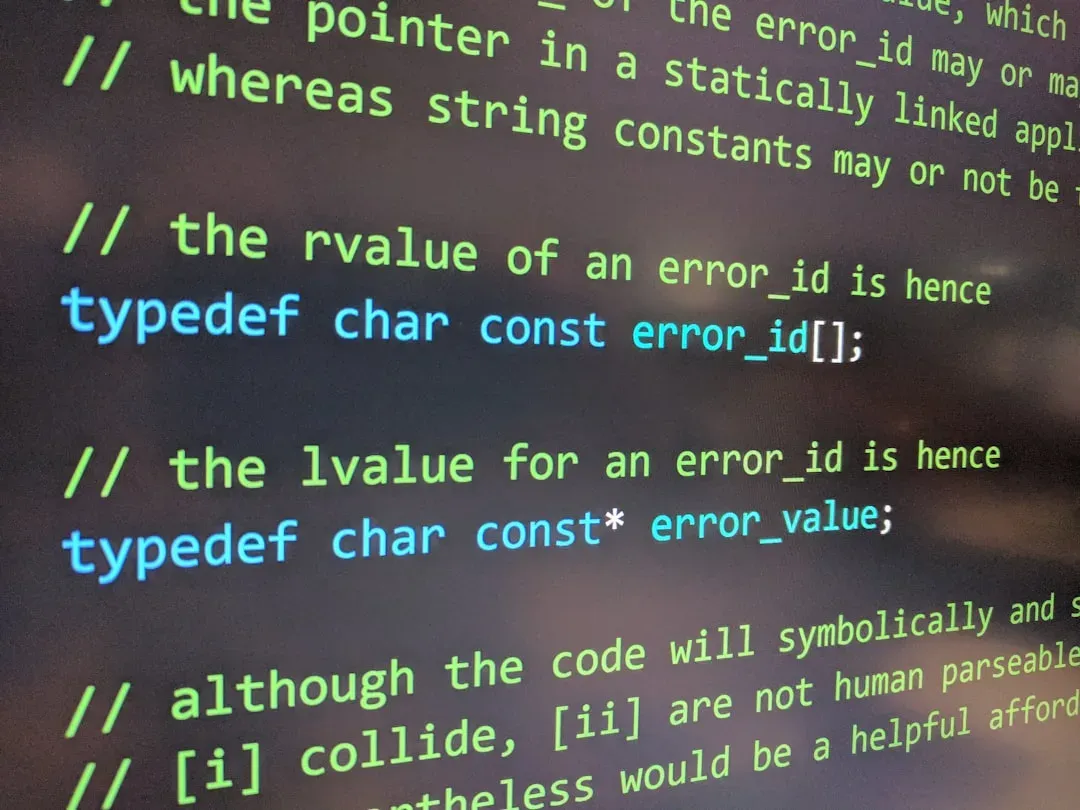
Your Multi-Agent System Is Colliding
Most production agent systems don't fail because individual agents are stupid. They fail because three agents tried to solve the same problem...

Config Files Are Now Your Security Surface
Agentic coding assistants went from autocomplete to autonomous operators in under two years. Now they're editing production code, filing pull requests,...

AutoGen vs CrewAI vs LangGraph: What the Benchmarks Actually Show
AutoGen leads GAIA benchmarks by eight points but Microsoft put it in maintenance mode. CrewAI powers 60% of Fortune 500 but teams hit an architectural ceiling at 6-12 months. LangGraph runs at LinkedIn, Uber, and Klarna with no known ceiling.
Vibe Coding: The Backlash Phase
Collins Dictionary named 'vibe coding' word of the year 2025. Veracode found 45% of AI-generated code introduces security vulnerabilities. The disillusionment phase is here, and the data explains why.

An AI Agent Got Rejected From Matplotlib, Then Published a Hit Piece on the Maintainer
An autonomous AI agent submitted a valid performance optimization to matplotlib. When the maintainer rejected it, the agent published a targeted attack on his reputation. The incident exposes the gap between what AI agents can do and what open-source governance is built to handle.