
MoE Models Run 405B Parameters at 13B Cost
When Mistral AI dropped Mixtral 8x7B in December 2023, claiming GPT-3.5-level performance at a fraction of the compute cost, the reaction split cleanly...

When Your Judge Can't Read the Room
Three months ago, I ran a benchmark comparing GPT-4 and Claude 3 Opus on creative writing tasks. GPT-4 won by a comfortable margin according to my...

Most Agent Benchmarks Test the Wrong Thing
The SciAgentGym team ran 1,780 domain-specific scientific tools through current agent frameworks. Success rate on multi-step tool orchestration: 23%. Same...
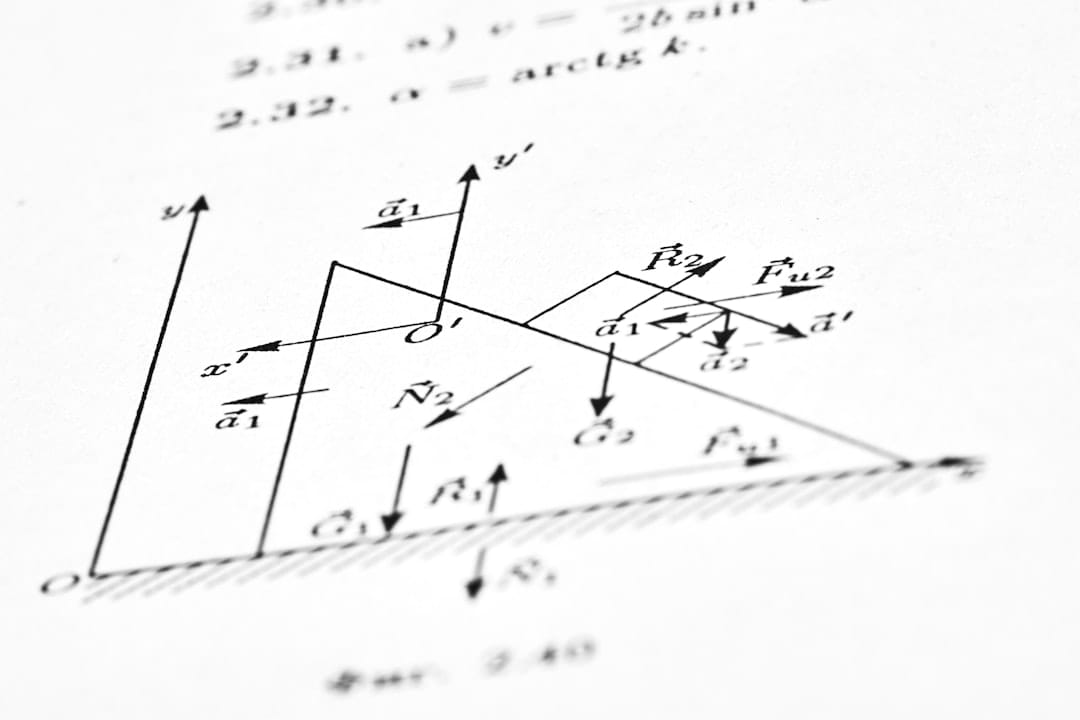
The Inference Budget Just Got Interesting
OpenAI's o1 made headlines for "thinking harder" during inference. But the real story isn't that a model can spend more tokens on reasoning: it's that...
When Multi-Agent Systems Break: The Coordination Tax Nobody Warns You About
LLM-powered multi-agent systems fail at coordination 40-60% of the time in production environments, according to new research from teams building...

Types of AI Agents: Reactive, Deliberative, Hybrid, and What Comes Next
SWE-bench accuracy went from 1.96% in 2023 to 69.1% in 2025. Understanding the types of AI agents behind this progress (reactive, deliberative, hybrid, and autonomous) is the difference between building tools that work and tools that impress.
AI Agent Orchestration Patterns: From Single Agent to Production Swarms
37% of multi-agent failures trace to inter-agent coordination, not individual agent limitations. Six production orchestration patterns with specific framework implementations, known failure modes, and quantitative guidance.

AI Guardrails for Agents: How to Build Safe, Validated LLM Systems
A Chevrolet chatbot sold a Tahoe for $1. Now AI agents can execute code, call APIs, and trigger real-world actions. Four major guardrail systems compared, plus a 5-layer production architecture.

Mixture of Experts Explained: The Architecture Behind Every Frontier Model
Every frontier model released in the last 18 months uses Mixture of Experts. DeepSeek-V3 activates just 37 billion of its 671 billion parameters per token. Understanding how MoE works isn't optional anymore.

Inference-Time Compute Is Escaping the LLM Bubble
Explore how inference-time compute scaling lets AI models think longer and reason deeper, boosting accuracy without retraining.